Which of the following is RISC processor?Pentium 4ARMCore i7C) ARMARM processors are based on RISC architecture (Reduced Instruction Set Computer).
Pipeline in computer architecture is used to:Decrease throughputIncrease instruction execution speedReduce clock speedC) Increase instruction execution speedPipelining improves CPU throughput by overlapping execution of instructions.
Cache memory is:Faster but smaller than RAMSame as virtual memorySecondary storageB) Faster but smaller than RAMCache provides very fast access to frequently used data.
Which type of control unit is faster?MicroprogrammedCISCPipelinedA) HardwiredHardwired control is faster but less flexible compared to microprogrammed control.
Von Neumann architecture uses:Single memory for data and instructionsNo memoryStack-based memoryB) Single memory for data and instructionsVon Neumann architecture stores both data and instructions in the same memory.
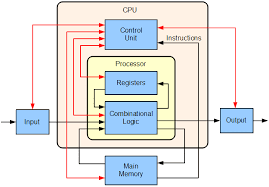
The control unit of a computer is responsible for:Directing data flow and instructionsPerforming arithmetic operationsDisplaying outputB) Directing data flow and instructionsThe control unit manages the execution of instructions by directing data flow between CPU components.
RISC architecture is characterized by:Simple instructions and more registersMicroprogrammed controlSlow pipeline performanceB) Simple instructions and more registersRISC (Reduced Instruction Set Computer) uses a small, highly optimized instruction set for efficiency.
The term “MAR” stands for:Memory Address RegisterMachine Access RegisterMemory Arithmetic RegisterB) Memory Address RegisterMAR holds the address of memory location to be accessed for read/write operations.
Pipelining improves CPU performance by:Reducing instruction setOverlapping execution of instructionsUsing more memoryC) Overlapping execution of instructionsPipelining executes multiple instructions simultaneously at different stages for faster throughput.
Which of the following is a hazard in pipelining?Memory AllocationContext SwitchingFile ManagementA) Data HazardData hazards occur when an instruction depends on the result of a previous instruction still in the pipeline
CPI stands for:Cycles Per InstructionControl Process InstructionCurrent Program InstructionB) Cycles Per InstructionCPI measures the average number of clock cycles taken to execute an instruction.
Harvard Architecture is different from Von Neumann because:It uses separate memory for code and dataIt has no ALU It cannot be pipelinedB) It uses separate memory for code and dataHarvard architecture separates instruction and data memory for parallel access.
Which of the following is NOT a type of computer interrupt?Software InterruptSpurious InterruptCache InterruptD) Cache InterruptThere is no "cache interrupt"; interrupts are typically hardware or software generated.
Micro-operations are:Assembly instructionsMemory allocationsBus transfersA) CPU-level operations on data stored in registersMicro-operations perform simple tasks like data transfer or arithmetic inside the CPU.
Flynn’s taxonomy classifies computers based on:Number of CPUsInstruction and data streamsOperating system typeC) Instruction and data streamsFlynn’s taxonomy divides computers into SISD, SIMD, MISD, and MIMD based on parallelism.
Pipelining improves:Instruction throughputMemory sizeInstruction setB) Instruction throughputPipelining overlaps instruction execution to increase overall throughput.
:Which register stores intermediate results in CPU?MDRAccumulatorPCC) AccumulatorThe accumulator temporarily holds results of arithmetic/logic operations.
Control unit generates:Control signalsProgram counter valuesCache blocksB) Control signalsThe control unit directs CPU operations using timing and control signals.
Which memory has highest latency?CacheMain MemoryVirtual Memory (Disk)D) Virtual Memory (Disk)Disk-based virtual memory is slowest compared to RAM and cache.
RISC architecture emphasizes:Simple, fast instructionsMicrocode usageVariable instruction lengthsB) Simple, fast instructionsRISC (Reduced Instruction Set Computing) uses fewer instructions executed quickly.
Harvard architecture separates:Data and InstructionsMemory and Cache: Control Unit and RegistersB) Data and InstructionsHarvard architecture uses separate memory for data and instructions.
Which addressing mode uses a constant value as operand?DirectIndirectIndexedA) ImmediateImmediate mode provides operand directly in instruction.
Micro-operations are performed by:MicroinstructionsCacheMemoryB) MicroinstructionsMicroinstructions control execution of low-level operations.
Cache mapping technique that uses associative memory is:Associative MappingSet-AssociativeRandom MappingB) Associative MappingAssociative mapping allows block to be placed anywhere in cache.
Which of the following improves instruction-level parallelism?Virtual MemorySpoolingDMAA) PipeliningPipelining overlaps execution of instructions to improve throughput.
The unit that translates assembly code to micro-operations is:Control UnitDecoderCacheB) Control UnitControl unit interprets instructions and generates signals for execution.
RISC processors are characterized by:Few simple instructionsVariable-length instructionsMicrocoded controlB) Few simple instructionsRISC architectures use simple instructions for faster execution.
Instruction pipelining suffers from:FragmentationDeadlocksPagingA) HazardsHazards (structural, data, control) cause delays in pipelines.
The carry flag is part of:Status RegisterInstruction RegisterStack PointerB) Status RegisterStatus register stores condition flags like carry, zero, sign.
Which memory is the fastest?CacheHard DiskVirtual MemoryB) CacheCache memory is the fastest, closer to CPU than RAM.
Flynn’s taxonomy classifies computers based on:Instruction and data streamsCache sizeControl signalsB) Instruction and data streamsFlynn’s taxonomy includes SISD, SIMD, MISD, MIMD architectures.
Which type of parallelism is exploited in instruction pipelining?Instruction-level parallelismThread parallelismProcess parallelismB) Instruction-level parallelismPipelining overlaps instruction execution stages.
Which bus carries control signals in CPU?Address busControl busSystem busC) Control busControl bus coordinates operations like read/write between components.
Which architecture uses a single instruction to operate on multiple data?SIMDMISDMIMDB) SIMDSIMD executes one instruction on multiple data streams.
Cache memory is placed between:CPU and DiskMain Memory and I/OCPU and RegistersA) CPU and Main MemoryCache speeds up access by storing frequently used data.
Which register holds the address of the next instruction?PCIRMDRB) PCProgram Counter stores the memory address of the next instruction.
RISC processors emphasize:Few simple instructionsVariable instruction lengthMicrocoded controlB) Few simple instructionsRISC reduces instruction complexity for speed.
Pipelining improves:ThroughputMemory capacityCache sizeB) ThroughputPipelining overlaps instruction execution to increase throughput.
Von Neumann architecture uses:Single bus for data and instructionsHarvard architectureNoneB) Single bus for data and instructionsIt uses the same memory for instructions and data.
ALU performs:Arithmetic and logical operationsMemory managementI/O operationsB) Arithmetic and logical operationsALU executes mathematical and logical instructions.
Which register holds temporary arithmetic results?AccumulatorPCMACB) AccumulatorAccumulator stores intermediate results of operations.
Instruction pipelining may cause:DeadlocksThrashingFragmentationA) HazardsPipeline hazards delay instruction execution.
Flynn’s taxonomy classifies computers based on:Instruction and data streamsClock speedCache levelsB) Instruction and data streamsFlynn’s taxonomy categorizes SISD, SIMD, MISD, MIMD.
MAR stands for:Memory Address RegisterMachine Address RegisterMain Access RegisterB) Memory Address RegisterMAR holds address of memory to be accessed.
Cache memory reduces:Memory access timeInstruction setBus widthB) Memory access timeCache provides fast access to frequently used data.
CISC uses:Large set of complex instructionsParallel pipelinesRISC principlesB) Large set of complex instructionsCISC supports many addressing modes.
Pipelining increases:Instruction throughputMemory sizeControl hazardsB) Instruction throughputMultiple instructions processed simultaneously.
Microprogrammed control unit is:MicroprogrammedRISCPipelinedB) MicroprogrammedUses control memory to generate signals.
The unit that translates a program’s instructions into signals the computer hardware can execute is:Control UnitRegisterCacheB) Control UnitThe control unit decodes instructions and directs operations.
Pipelining improves:ThroughputClock speedMemory sizeB) ThroughputMultiple instructions overlap execution, increasing instruction throughput.
Which of the following is a RISC processor?ARMPentiumCore i7B) ARMARM follows RISC principles with simple instructions.
The speed of CPU is measured in:MHz/GHzFLOPSCPIB) MHz/GHzCPU clock speed is measured in Hertz.
Which register stores the address of the next instruction?PCIPMDRB) PCProgram Counter (PC) holds the address of the next instruction.
Flynn’s taxonomy classifies computers based on:Instruction and data streamsStorage devicesBus structureB) Instruction and data streamsFlynn’s taxonomy categorizes SISD, SIMD, MISD, MIMD.
Pipelining in processors improves:Instruction execution speedMemory capacityCache hit rateB) Instruction execution speedPipelining allows overlapping instruction execution.
The CPI (Cycles Per Instruction) depends on:Pipeline depthCache performanceAll of the aboveD) All of the aboveCPI is influenced by multiple architecture factors.
Cache memory is usually built using:DRAMFlash memoryMagnetic diskA) SRAMCache is built from SRAM for high speed.
Which addressing mode uses the actual operand in the instruction?ImmediateIndirectIndexedB) ImmediateImmediate mode encodes operand directly in instruction.
Superscalar processors achieve higher performance by:Executing multiple instructions per cycleReducing memory sizeUsing virtual memoryB) Executing multiple instructions per cycleSuperscalar processors exploit instruction-level parallelism.
The main advantage of Harvard architecture over Von Neumann is:Separate instruction and data pathsHigh memory capacitySimpler designB) Separate instruction and data pathsHarvard architecture reduces bottlenecks.
The speed of a processor is measured in:BytesCPIMIPSA) HertzCPU clock speed is measured in Hz (cycles per second).
Which technique allows multiple instructions to overlap in execution?PipeliningBranchingSpoolingB) PipeliningPipelining increases CPU throughput by overlapping execution stages.
Flynn’s taxonomy classifies computers based on:Cache sizeInstruction setClock speedA) Instruction and data streamsIt categorizes as SISD, SIMD, MISD, and MIMD.
Which memory is closest to the CPU?CacheRegisterHard DiskC) RegisterRegisters are small, fast storage directly inside the CPU.
Which architecture uses fewer instructions for faster execution?RISCVLIWSISDB) RISCRISC architectures simplify instructions for performance.
Which is the fastest type of memory in a computer system?RAMHard DiskVirtual MemoryA) CacheCache memory is small but extremely fast.
The control unit of a computer is responsible for:Executing arithmetic operationsDirecting the flow of instructionsPerforming I/OC) Directing the flow of instructionsThe control unit manages instruction execution.
Pipelining in processors improves:Instruction throughputMemory sizeCache replacementB) Instruction throughputPipelining allows overlapping of instruction stages, increasing throughput.
What is the size of an instruction word in a 32-bit architecture?8 bytes2 bytes1 bytesA) 4 bytesIn 32-bit systems, instruction size is typically 4 bytes.
RISC architecture focuses on:Simple instructions executed quicklyHigh memory bandwidthLow-level machine languageB) Simple instructions executed quicklyRISC (Reduced Instruction Set Computer) uses simple, fast instructions.
Which register holds the address of the next instruction to be executed?Program CounterAccumulatorMARB) Program CounterPC tracks the address of the next instruction.